openpyxlはPythonからExcelを操作するためのパッケージです。Excelファイルを開いて値を取得したり、値を変更してExcelファイルに保存したりできます。
ただし、今のところopenpyxlはExcelの機能に完全に対応していないので注意も必要です。図形やグラフがあるExcelファイルを開いて保存する場合、図形やグラフが消えたり、結合したセルの罫線も崩れたりします。
このように多少の制限はありますが、openpyxlでExcel作業を自動化するのは非常に便利です。セルの値の参照や設定は問題なくできます。Excelファイルを更新し、それを保存するような場合だけ注意すれば、ほとんどの場合は大丈夫でしょう。オリジナルのファイルも念のため残しておくと良いでしょう。
openpyxlを使う前の準備
openpyxlパッケージののインストール
openpyxlパッケージをはpipコマンドでインストールします。
pip install openpyxlAnacondaを使っている場合はcondaコマンドでもインストールできます。
conda install openpyxlExcelについて知っておくこと
実際に使い始める前に操作対象であるExcelの用語などついて簡単におさらいしておきましょう。
Excel文書はブックという単位で作成され、1つのブックが1つのファイルとして保存されます。
ブックは複数のシートを持つことができ、シートには多くのセルがあります。
1つのセルは列と行の座標で特定されます。列の位置は「A、B、C、…」といったアルファベットで示され、行の位置は「1、2、3、…」といった数値で示されます。このような指定方法は「A1参照形式」と言います。行と列を共に数値で指定することもでき、これは「R1C1参照形式」と言います。
ブック、シート、セルはExcel文書を構成する基本要素です。openpyxlでブック、シート、セルは、それぞれWorkbookオブジェクト、Worksheetオブジェクト、Cellオブジェクトで表されます。
ワークブック(Excelファイル)の操作
openpyxlでExcelのブックはWorkbookオブジェクトで表されます。Excelファイルを読み込むとWorkbookオブジェクトが返されます。WorkbookオブジェクトをExcelファイルに保存することもできます。
なおこの後の例は、すべて次の文を実行してopenpyxlをインポートしているものとします。
>>> import openpyxlExcelファイルを開く
Excelファイルを開くにはopenpyxl.load_workbook()関数を使います。引数にExcelファイルの名前を指定します。
>>> wb = openpyxl.load_workbook('sample.xlsx')
>>> type(wb)
<class 'openpyxl.workbook.workbook.Workbook'>openpyxl.load_workbook()は、ファイルを開くとWorkbookオブジェクトを返します。
新しいワークブックを作成する
新規ワークブックを作成するには、openpyxl.Workbook()関数を使います。openpyxl.Workbook()は、新しいWorkbookオブジェクトを作成して返します。
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
['Sheet']新規作成したワークブックはSheetという名前のシートを1つだけ持っています。
Excelファイルに保存する
ワークブックをExcelファイルに保存するには、Workbookオブジェクトのsave()メソッドを使います。引数には保存するファイル名を指定します。
すでにファイルが存在する場合、警告なしにファイルを上書きしてしまうので注意してください。
>>> wb = openpyxl.Workbook()
>>> wb.save('save.xlsx')ワークシートの操作
Excelのシートは、openpyxlのWorksheetオブジェクトで表されます。ここではワークシートに関連する操作を紹介します。
ワークシートの一覧を取得する
Workbookオブジェクトは、ブックが持つすべてのシート名をsheetnames属性に保存しています。このsheetnames属性を参照することでワークシートの一覧を得ることができます。
>>> wb.sheetnames
['Sheet2', 'New Title', 'Sheet1']ワークシートを取得する
Workbookオブジェクトのキーにワークシートの名前を指定して、Worksheetオブジェクトを得ることができます。
>>> ws = wb['Sheet']
>>> type(ws)
<class 'openpyxl.worksheet.worksheet.Worksheet'>アクティブなワークシートを取得する
アクティブなワークシートを取得するにはactive属性を参照します。
>>> ws = wb.activeワークシートの名前の取得と変更
ワークシートの名前はWorksheetオブジェクトのtitle属性を参照することで確認できます。
>>> wb = openpyxl.Workbook()
>>> ws = wb.active
>>> ws.title
'Sheet'名前を変更するには、title属性に新しい名前を設定します。
>>> ws.title = 'New name'
>>> ws.title
'New name'新しいワークシートを作成する
ワークシートを新規作成するには、Workbookオブジェクトのcreate_sheet()メソッドを使います。引数にシートの名前を指定します。
作成したシートは、すべてのシートの末尾に追加されます。
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
['Sheet']
>>> ws = wb.create_sheet('foo')
>>> type(ws)
<class 'openpyxl.worksheet.worksheet.Worksheet'>
>>> ws.title
'foo'
>>> wb.sheetnames
['Sheet', 'foo']create_sheet()の引数を省略するとシートはSheetN(Nは整数)という名前で作成されます。
>>> wb.create_sheet()
<Worksheet "Sheet1">
>>> wb.sheetnames
['Sheet', 'foo', 'Sheet1']
>>> wb.create_sheet()
<Worksheet "Sheet2">
>>> wb.sheetnames
['Sheet', 'foo', 'Sheet1', 'Sheet2']特定の位置にシートを挿入することもできます。それには挿入する位置のインデックスを指定します。インデックス0は先頭にシートを挿入します。
>>> ws = wb.create_sheet('foo', 0)
>>> wb.sheetnames
['bar', 'Sheet', 'foo', 'Sheet1']キーワード引数を使うこともできます。
>>> wb.create_sheet(title='hoge', index=2)
<Worksheet "hoge">
>>> wb.sheetnames
['bar', 'Sheet', 'hoge', 'foo', 'Sheet1', 'Sheet2']ワークシートを削除する
ワークシートを削除するには、Workbookオブジェクトのremove()メソッドを使います。引数に削除するWorksheetオブジェクトを指定します。
>>> wb.sheetnames
['bar', 'Sheet', 'hoge', 'foo', 'Sheet1', 'Sheet2']
>>> wb.remove(wb['Sheet'])
>>> wb.sheetnames
['bar', 'hoge', 'foo', 'Sheet1', 'Sheet2']ワークシートをコピーする
Workbookオブジェクトのcopy_worksheet()メソッドを使えば、ワークシートをコピーできます。引数にコピーするWorksheetオブジェクトを指定します。copy_worksheet()メソッドはコピーされたWorksheetオブジェクトを返します。
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
['Sheet']
>>> copy = wb.copy_worksheet(wb['Sheet'])
>>> wb.sheetnames
['Sheet', 'Sheet Copy']
>>> copy.title = 'new_name'
>>> wb.sheetnames
['Sheet', 'new_name']copy_worksheet()はコピーのWorksheetオブジェクトを返しますので、そのオブジェクトで適切な名前を設定できます。
なお、ワークブック間でワークシートのコピーはできません。読み取り専用や書き込み専用モードでワークブックを開いている場合もワークシートのコピーはできません。
セルの操作
Excelのセルは、openpyxlではCellオブジェクトで表されます。Cellオブジェクトを操作することでセルの値を参照したり、値を設定したりすることができます。
Cellオブジェクトを取得する(A1参照形式)
WorksheetオブジェクトからA1参照形式でCellオブジェクトを取得することができます。Worksheetオブジェクトのキーに座標(A1参照形式)を文字列で指定します。
>>> wb = openpyxl.Workbook()
>>> ws = wb.active
>>> cell = ws['A1']Cellオブジェクトを取得する(R1C1参照形式)
列を数値で指定したければ、Worksheetオブジェクトのcell()メソッドを使います。キーワード引数rowおよびcolumnに列と行の位置を指定します。左上角のセルは「row=1, column=1」です。
>>> cell = ws.cell(row=1, column=1)
>>> cell
<Cell 'Sheet'.A1>セルの値を参照する
セルの値を参照するにはCellオブジェクのvalue属性を参照します。
>>> wb = openpyxl.Workbook()
>>> ws = wb.active
>>> ws['A1'] = '36'
>>> ws['A2'] = 3準備として、まず参照する値を設定しました。それでは値を参照して見ましょう。
>>> a1 = ws['A1']
>>> a1.value
'36'
>>> a2 = ws['A2']
>>> a2.value
3実務では、次のように短く値を参照することが多いでしょう。
>>> ws['A1'].value
'36'
>>> ws.cell(row=2, column=1).value
3文字列で設定した値を参照すると文字列が返され、数値で設定した値は数値で返されていることに注目してください。Excelではセルの値を数値や文字列などに設定できるため、値を参照するときはセルのデータ型に注意が必要です。
セルに値を設定する
セルに値を設定するには、Cellオブジェクトに値を代入します。
>>> wb = openpyxl.Workbook()
>>> ws = wb.active()
>>> a1 = ws['A1']
>>> a2 = ws['A2']
>>> a1 = 'Hello world!'
>>> a2 = 3.14次のように短く書くことも多いでしょう。
>>> ws['A1'] = 'Hello world!'R1C1参照形式を使う場合は、Worksheetオブジェクトのcell()メソッドを使い、キーワード引数valueに値を指定します。
>>> ws.cell(row=2, column=1, value=3.14)
<Cell 'Sheet'.A2>
>>> ws.cell(row=2, column=1).value
3.14A1参照形式とR1C1参照形式を変換する
openpyxlで処理を自動化するときは、列を数値で指定する方が簡単です。しかしユーザーは列をアルファベットで指定することに慣れています。このためopenpyxlには、列のアルファベットと数値を相互に変換できるユーティリティ関数が用意されています。
openpyxl.utils.column_index_from_string()関数はアルファベットを数値へ変換します。
>>> from openpyxl.utils import get_column_letter, column_index_from_string
>>> column_index_from_string('A')
1
>>> column_index_from_string('AZ')
52openpyxl.utils.get_column_letter()関数は数値をアルファベットへ変換します。
>>> get_column_letter(1)
'A'
>>> get_column_letter(27)
'AA'実用的な繰り返し(ループ)処理
Excel作業を自動化するのに繰り返し処理は欠かせません。すべてのワークシートを繰り返し処理したり、すべてのセルを繰り返し処理するなどです。ここでは実務に役立つ繰り返し処理を見ていきましょう。
ワークシートを順に参照する
ワークブックをforでループすると、すべてのワークシートを順に参照できます。
>>> wb.sheetnames
['foo', 'bar', 'hoge']
>>> for sheet in wb:
... print(sheet.title)
...
foo
bar
hogeここでは3つのワークシートを持ったワークブックをforでループしています。ワークシートが順にsheetに代入されるので、forの本体で必要な処理を実施します(この例ではシートの名前を表示しているだけ)。
この後の例はすべて次のExcelファイルを使います。
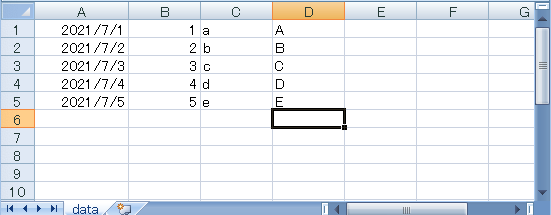
次のようにファイルを読み込んで、ワークシートオブジェクトを取得しているものとします。
>>> wb = openpyxl.load_workbook('sample.xlsx')
>>> ws = wb.active
すべての行データを順に参照する
ワークシートのすべての行データを順番に参照するには、Worksheetオブジェクトのrows属性をforでループします。
>>> for r in ws.rows:
... print(r)
...
(<Cell 'data'.A1>, <Cell 'data'.B1>, <Cell 'data'.C1>, <Cell 'data'.D1>)
(<Cell 'data'.A2>, <Cell 'data'.B2>, <Cell 'data'.C2>, <Cell 'data'.D2>)
(<Cell 'data'.A3>, <Cell 'data'.B3>, <Cell 'data'.C3>, <Cell 'data'.D3>)
(<Cell 'data'.A4>, <Cell 'data'.B4>, <Cell 'data'.C4>, <Cell 'data'.D4>)
(<Cell 'data'.A5>, <Cell 'data'.B5>, <Cell 'data'.C5>, <Cell 'data'.D5>)ご覧のように行データはタプルで、その要素はCellオブジェクトです。
特定の範囲の行データを順に参照する
すべての行ではなく、特定の範囲の行を順にループするにはWorksheetオブジェクトのiter_rows()メソッドを使います。iter_rows()は行だけでなく列の範囲も制限できます。
まずは引数を指定しないで実行してみます。引数をすべて省略するとWorksheetのrows属性を使ったときと同様に、(すべての列の要素を持った)すべての行をループできます。
>>> for r in ws.iter_rows():
... print(r)
...
(<Cell 'data'.A1>, <Cell 'data'.B1>, <Cell 'data'.C1>, <Cell 'data'.D1>)
(<Cell 'data'.A2>, <Cell 'data'.B2>, <Cell 'data'.C2>, <Cell 'data'.D2>)
(<Cell 'data'.A3>, <Cell 'data'.B3>, <Cell 'data'.C3>, <Cell 'data'.D3>)
(<Cell 'data'.A4>, <Cell 'data'.B4>, <Cell 'data'.C4>, <Cell 'data'.D4>)
(<Cell 'data'.A5>, <Cell 'data'.B5>, <Cell 'data'.C5>, <Cell 'data'.D5>)しかしrows属性と異なり、iter_rows()はCellオブジェクトではなく、セルの値を返すこともできます。それには、キーワード引数values_onlyにTrueを指定します。
>>> for r in ws.iter_rows(values_only=True):
... print(r)
...
(datetime.datetime(2021, 7, 1, 0, 0), 1, 'a', 'A')
(datetime.datetime(2021, 7, 2, 0, 0), 2, 'b', 'B')
(datetime.datetime(2021, 7, 3, 0, 0), 3, 'c', 'C')
(datetime.datetime(2021, 7, 4, 0, 0), 4, 'd', 'D')
(datetime.datetime(2021, 7, 5, 0, 0), 5, 'e', 'E')
行の範囲を制限するにはキーワード引数min_rowとmax_rowを使います。
>>> for r in ws.iter_rows(min_row=2, max_row=4):
... print(r)
...
(<Cell 'data'.A2>, <Cell 'data'.B2>, <Cell 'data'.C2>, <Cell 'data'.D2>)
(<Cell 'data'.A3>, <Cell 'data'.B3>, <Cell 'data'.C3>, <Cell 'data'.D3>)
(<Cell 'data'.A4>, <Cell 'data'.B4>, <Cell 'data'.C4>, <Cell 'data'.D4>)列の範囲を制限することもできます。それにはキーワード引数min_colとmax_colを使います。
>>> for r in ws.iter_rows(min_row=2, max_row=4, min_col=2, max_col=3):
... print(r)
...
(<Cell 'data'.B2>, <Cell 'data'.C2>)
(<Cell 'data'.B3>, <Cell 'data'.C3>)
(<Cell 'data'.B4>, <Cell 'data'.C4>)
すべての列データを順に参照する
ワークシートのすべての列データを順番に参照するには、Worksheetオブジェクトのcolumns属性をforでループします。
>>> for c in ws.columns:
... print(c)
...
(<Cell 'data'.A1>, <Cell 'data'.A2>, <Cell 'data'.A3>, <Cell 'data'.A4>, <Cell 'data'.A5>)
(<Cell 'data'.B1>, <Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>, <Cell 'data'.B5>)
(<Cell 'data'.C1>, <Cell 'data'.C2>, <Cell 'data'.C3>, <Cell 'data'.C4>, <Cell 'data'.C5>)
(<Cell 'data'.D1>, <Cell 'data'.D2>, <Cell 'data'.D3>, <Cell 'data'.D4>, <Cell 'data'.D5>)列データはCellオブジェクトを要素に持つタプルです。
特定の範囲の列データを順に参照する
すべての列ではなく、特定の範囲の列を順にループするにはWorksheetオブジェクトのiter_cols()メソッドを使います。iter_cols()は列だけでなく行の範囲も制限できます。
引数を指定しないで実行すると、Worksheetのrows属性を使ったときと同様に、(すべての行の要素を持った)すべての列をループできます。
>>> for c in ws.iter_cols():
... print(c)
...
(<Cell 'data'.A1>, <Cell 'data'.A2>, <Cell 'data'.A3>, <Cell 'data'.A4>, <Cell 'data'.A5>)
(<Cell 'data'.B1>, <Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>, <Cell 'data'.B5>)
(<Cell 'data'.C1>, <Cell 'data'.C2>, <Cell 'data'.C3>, <Cell 'data'.C4>, <Cell 'data'.C5>)
(<Cell 'data'.D1>, <Cell 'data'.D2>, <Cell 'data'.D3>, <Cell 'data'.D4>, <Cell 'data'.D5>)iter_rowsと同様、iter_colsのキーワード引数values_onlyにTrueを指定すると、Cellオブジェクトではなくセルの値が返されます。
>>> for c in ws.iter_cols(values_only=True):
... print(c)
...
(datetime.datetime(2021, 7, 1, 0, 0), datetime.datetime(2021, 7, 2, 0, 0), datet
ime.datetime(2021, 7, 3, 0, 0), datetime.datetime(2021, 7, 4, 0, 0), datetime.da
tetime(2021, 7, 5, 0, 0))
(1, 2, 3, 4, 5)
('a', 'b', 'c', 'd', 'e')
('A', 'B', 'C', 'D', 'E')列の範囲を制限するにはキーワード引数min_colとmax_colを使います。次の例は2列目から3列目までをループします。
>>> for c in ws.iter_cols(min_col=2, max_col=3):
... print(c)
...
(<Cell 'data'.B1>, <Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>, <Cell 'data'.B5>)
(<Cell 'data'.C1>, <Cell 'data'.C2>, <Cell 'data'.C3>, <Cell 'data'.C4>, <Cell 'data'.C5>)行の範囲を制限するにはキーワード引数min_rowとmax_rowを使います。
>>> for c in ws.iter_cols(min_col=2, max_col=3, min_row=2, max_row=4):
... print(c)
...
(<Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>)
(<Cell 'data'.C2>, <Cell 'data'.C3>, <Cell 'data'.C4>)行や列、矩形領域を参照する
ワークシートのある行や列、矩形領域を切り出すこともできます。これにはPythonのスライスの記法を使います。
ここでは引き続きsample.xlsxから読み込んだデータを使います。
行のデータを取得する
行のデータを取得するには、次のようにワークシートに行番号を指定します。
>>> row2 = ws[2]
>>> row2
(<Cell 'data'.A2>, <Cell 'data'.B2>, <Cell 'data'.C2>, <Cell 'data'.D2>)複数の行を切り出すには、次のようにコロンで区切って指定します。次の例では2行目から4行目までを切り出します。
>>> row2_4 = ws[2:4]
>>> row2_4
((<Cell 'data'.A2>, <Cell 'data'.B2>, <Cell 'data'.C2>, <Cell 'data'.D2>),
(<Cell 'data'.A3>, <Cell 'data'.B3>, <Cell 'data'.C3>, <Cell 'data'.D3>),
(<Cell 'data'.A4>, <Cell 'data'.B4>, <Cell 'data'.C4>, <Cell 'data'.D4>))列のデータを取得する
列のデータを取得するには、ワークシートに列のアルファベットを指定します。
>>> colb = ws['B']
>>> colb
(<Cell 'data'.B1>, <Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>, <Cell 'data'.B5>)複数の列を切り出すには、次のようにコロンで区切って指定します。
>>> colb_c = ws['B:C']
>>> colb_c
((<Cell 'data'.B1>, <Cell 'data'.B2>, <Cell 'data'.B3>, <Cell 'data'.B4>, <Cell 'data'.B5>),
(<Cell 'data'.C1>, <Cell 'data'.C2>, <Cell 'data'.C3>, <Cell 'data'.C4>, <Cell 'data'.C5>))矩形領域を取得する
矩形領域のデータを取得するには、左上の座標と右下の座標を指定します。
>>> rect = ws['B2:C4']
>>> rect
((<Cell 'data'.B2>, <Cell 'data'.C2>),
(<Cell 'data'.B3>, <Cell 'data'.C3>),
(<Cell 'data'.B4>, <Cell 'data'.C4>))切り出したデータはネストしたタプルで返されます。
おわりに
ここで紹介したものは、openpyxlの基本的な部分だけですが、これだけでもExcel作業の多くを自動化できるでしょう。
openpyxlは、このほかにもセルの書式設定、罫線、セルの結合などExcelの多くの機能に対応しています。機会があればこれらの機能も紹介して見たいと思います。